
BearID Project
BearID To Go

If you have been following the BearID Project, then you know we have developed an application to identify individual bears from photographs. The application is published on GitHub as bearid and the supporting deep learning networks are published at bearid-models (currently trained with bears from Katmai National Park in Alaska and Glendale Cove in British Columbia). Running the application is fairly simple, you call it like this:

where is the path to your images or a directory. It seems easy enough!
However, to get to that point, you need to download and build all the bearid binaries. This requires installation of various libraries like the Open Basic Liner Algebra Subprograms library (OpenBLAS), the Boost library (boost) and Dlib. We developed this using the Linux machine, nicknamed Otis, which we put together a few years back (see Building a Deep Learning Computer), so you need to deal with tools like GNU C++ Compiler and cmake and worry about compatibility with the X Windows System. Now it’s starting to get complicated.
The aim for the BearID Project is for it to be used by non-computer scientists, like our conservation biologist, Dr. Melanie Clapham. Melanie uses a Windows laptop in the field, and Mary and I use Otis or our MacBooks. One option could be to migrate everything to the cloud. We could then support a single OS there. Unfortunately, when Melanie is in the field, her Internet access is very limited, so having something running on her laptop would be extremely beneficial. So now what?
Enter Docker

Docker is a set of services that utilizes virtualization to deliver software in containers. A Docker container is a virtual machine that can run within the Docker Engine across a number of supported host operating systems. Everything needed to run inside the container is delivered as a Docker image. The Docker image includes the operating system, libraries and application. Once you have an image, to can run it on top of any host operating system that supports the Docker Engine, including Linux, Windows and macOS. It can run on a local machine or in the cloud. Once we have a docker container, we can run it just about anywhere we need to. So let’s get started…
The Dockerfile
I’ll assume you are already familiar with Docker. If not, I recommend Getting Started with Docker. For more details, check out the Docker overview.
For our journey, the first step was to build up an image. This started with a Dockerfile, which tells Docker where to get all the components you want to use in your image. There are a lot of images you can start with, have a look on Docker Hub. Our main program, bearid, is Python 3 code and we prefer Linux. So we started with a Debian image with Python installed, called python:3.7-slim. You pull this in to your image using the FROM command in your Dockerfile like this:

Next, you add in all the packages you need for your application. Use Docker’s RUN command to call the relevant OS commands. For Debian, this means using apt-get for the packages. Our core application is C++ and uses dlib. To build it, we need tools like cmake and wget and libraries like Boost and BLAS. While we won’t have a GUI, part of out application does draw in image buffers using some X11 tools, so we need that too. So after our FROM call, we have something like:

We are using dlib 19.7, so we’ll get that next:

We use a tool called imglab from dlib to create XML files of all the images we will process. So we need to build and install that tool:

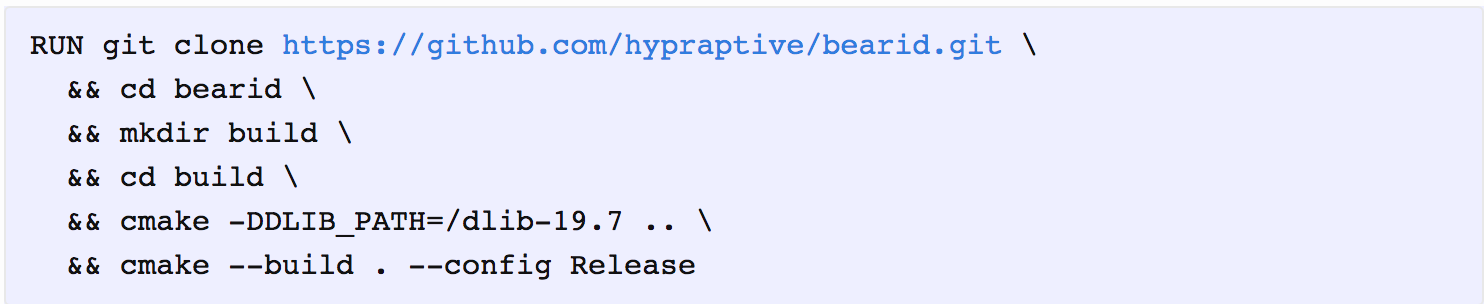
Now let’s get the bearid code from our GitHub repo and build it:
Finally, we need to get the pretrained models from our bearid-models repo:

Once you have all the components, you need to tell Docker what to run when the container is instantiated. You do this with the CMD command, which may look something like this:

Building the image
Now the Dockerfile is complete. The next step is to build the image using the docker build command. You may want to tag the image so it is easy to reference. We used bearid as our tag. The build command is as simple as:

Staged builds
Now we have all the pieces we need in our Docker image. In fact, we have a little too much in there! Our initial bearid image was around 2GB! It turns out a lot of the development tools take up a lot of space and aren’t really needed to run the application. So to reduce the size of the final image, we used a staged build. The idea is to build 2 images. The first will have everything we need to build the application and the second will only have what we need to run the application.
The first stage is most of what we had above, but we name the first stage by adding an AS clause to the FROM command:

The first stage includes everything up to and including getting the bearid-models. At that point we start a new image by calling the FROM command again. You can use a completely different image in your FROM command if there exists a smaller but compatible image. We decided to stick with python:3.7-slim. We don’t need cmake or wget, but we do still need the X11, BLAS and Boost libraries, so we apt-get those:

Next we want to copy the executable we built over to our new image. We do this with the COPY command. Remember that AS bearid-build clause we added above, now we use that to tell COPY where to copy from. We will copy the bearid binaries, bearid.py, imglab and the models to the root of our new image:

Again we need to tell Docker how to run you code with CMD. You can also tell Docker where your working directory should be with the WORKDIR command:

With this staged build approach, our bearid image ended up being 388MB, about 1/6th the original size! You can find our latest Dockerfile here.
Running locally
Running an image involves the use of docker run. There are a couple useful flags to include. For example, -i keeps STDIN open and -t allocates a pseudo-TTY terminal. These are especially useful if you need basic interaction (for example, we print some status to the terminal). The --rm flag is useful to automatically remove the container instance after exiting. Otherwise you end up with a bunch of stopped containers lying around. We also use the -v flag to bind mount a volume to the container. This is how we pass in the photos we want to identify from the host OS to the container. The argument for -v looks like :. Our run command looks like this:

Running the bearid Docker image looks like this:
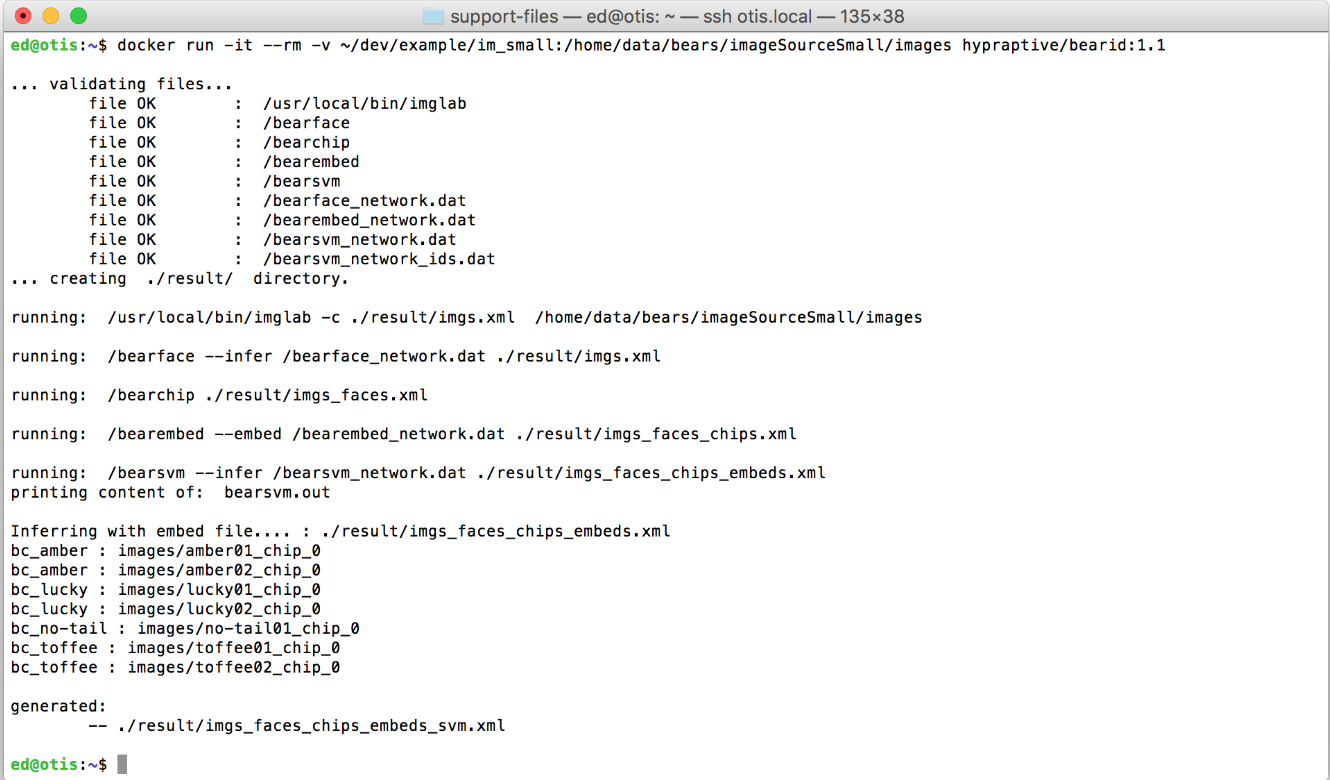
You can see that the bearid container checks for all the relevant files, runs through the underlying programs then prints out the bear ID predictions for the images. In this test case, there were 7 images. The predictions are in the format : . Note the images in the list all have _chip_0 in the name. This is actually showing the name of the chip file, containing only the bear’s face, produced by bearchip. If more than one face is found in an image, you would see _chip_1, _chip_2, etc.
The text print out is interesting, but you really want to see the image with the boxes and labels. For that, bearid outputs an XML file with all the relevant data and writes it back to the directory containing the source files (Remember from before?). Along with this XML file is an XSL file which is a stylesheet for the XML which transforms it into something viewable. If you have a browser that supports viewing and loading from local files, you can view this file directly. This works well with Firefox and Internet Explorer (for Chrome and Safari, you may have to jump through a few hoops and disable some security features). Here’s the XML file viewed in Firefox:

Publishing an image
Once we have a working Docker image, we can publish it for others to use. That way they don’t even need to run through the build process! For this we created repository on Docker Hub using our hypraptive Docker ID. A published image needs to have a unique name, for which need to use the proper namespace. We tag the the repository with with a string of the form

For our application we used hypraptive/bearid:1.1. After that, we push the image to the repository using docker push. You may need to log in to your Docker account using docker login. The command lines to tag and push our image are:

The docker push command will upload the image to Docker Hub in chunks. The time for this to complete will vary depending on the image size and your upload speed. It’s a good thing we reduced the size of the image using a staged build!
Running in the wild
Now that hypraptive/bearid is published on Docker Hub, anyone can run it anywhere Docker is running. You will need an Internet connection to download the image the first time, but after that it will run from your local file system. Running the container looks like before when running locally, except now we use the full namespace (and currently the version tag 1.1):

So far, we have been testing this process on our local Linux machine (Otis) and MacBook laptops. The goal was to enable Melanie to run this on her Windows laptop. To accomplish this, Melanie installed Docker Desktop for Windows on her laptop. She had to fiddle a bit with the amount of memory allocated to Docker images in the Docker Desktop (see the Resource settings for your host platform: Mac or Windows). Our application needs ~3GB to run, but she had less than 2GB available. By scaling the input images down to around 640x480, the bearid image can run in 1.2GB, and it still works pretty well. Once that was set up, she ran the command line above, and voila!

Now that she has this running on her laptop, she can take it into the field and use it remotely! She will only need internet access if we push any new updates to the Docker Hub repository.
If you happen to have photos of bears from Katmai or Glendale Cove and want to see if bearid can identify them, give it a try yourself!
Visit the BearID Project to learn more.
Add the first post in this thread.