
Tom August
- @tom_august
- | he/him



So, we (mainly @albags ) have done some tests to compare the camera we currently use in the AMI-trap with the range of cameras that are available for the Pi. I said in a thread somewhere that I would share our results, I can't find that thread, so here are the results.
First, the cameras we tested were:

And the Hawkeye could not run at the full potential of 64MP because the Raspberry Pi we were using was not powerful enough, so it is at 32MP in the below.
Here is the standard image that we took with each of the camera, though in the results I'm just going to show you a small part of each image so you can really get an idea of the variation in quality. The board had a 'test card' print out on it with a few moth wings attached for good measure.

In the comparison you can see that all the Pi cameras are better than the webcam and are also much smaller and cheaper. There is not a big difference between the two mid-range cameras but the hawkeye is better quality, even running at half the resolution it can do. The Hawkeye is picking up individual scales on the butterfly's wing. That might be overkill for many applications, and generates bit image files, but if you need that kind of resolution its pretty good!

9 May 2023 12:44pm
Hi Tom and Alba,
great comparison! From what distance did you take the images?
It would be interesting to also check the respective power consumption of the cameras while recording images and the latency (how long does it take to save the image in full resolution) on RPi 4/Zero. Also I'm wondering how the slightly improved image quality (e.g. between Pi camera 3 and IMX519) would actually affect classification accuracy during deployment. I'm pretty sure that there will be no difference regarding only detection, and the impact on classification probably depends on the differences between classes.
From some tests that I did with a YOLOv5s-cls classification model, trained on our classification dataset (only group level), I got the feeling that even significant downscaling (50%, so only half of the pixels are "kept" from the original image) will only lead to a minor decrease in classification accuracy. Of course this will depend heavily on the dataset and more classes with finer details/differences will probably be classified with a higher accuracy if you use a higher resolution of the input images.
There is definitely still a lot of potential for testing different recording hardware and its impact on automated detection/classification, especially regarding the trade-off between accuracy, speed, power consumption and disk storage.
Best,
Max







5 September 2023 8:12am
And this is a piece of the event reporting page, each of the buttons to the right of the event name can be clicked on to see a video of the event from that particular camera perspective. The whole system is configurable via a gui and has the concept of "state" that can be controlled with mobile phone buttons that control the actions that are executed by input events, which in this case are triggers from the object detector.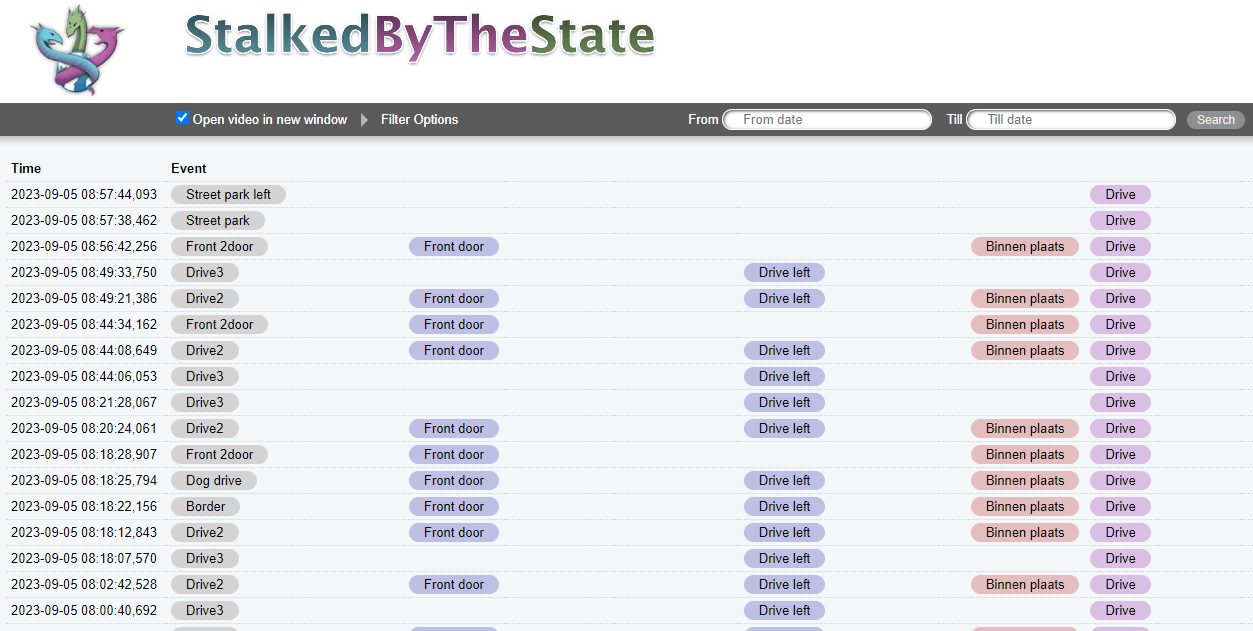
5 September 2023 8:16am
And finally for now, the object detectors are wrapped by a python websocket network wrapper to make it easy for the system to use different types of object detectors. Usually, it's about 1/2 a day for me to write a new python wrapper for a new object detector type. You just need to wrap in the network connection and make it conform to the yolo way of expressing the hits, i.e. the json format that yolo outputs with bounding boxes, class names and confidence level.
What's more, you can even use multiple object detector models in different parts of a single captured image and you can cascade the logic to require multiple object detectors to match for example, or a choice from different object detectors.
It's the perfect anti-poaching system (If I say so myself :) )

1 December 2025 3:39am
Have your findings/recommendations changed since 2023 on possible RPi cameras?
Has there been experience trying to use the different cameras (particularly the Hawkeye) in hot climates? The Pi Camera 3 lasts only a few months here before the lens cover/filter becomes all milky.
And is it correct that the IMX519 and Hawkeye work for our purposes without additional lenses?
Maximilian Sittinger