
Hello everyone,
👉 “Within the framework of the project
https://wildlabs.net/discussion/wildlabs-awards-2025-open-source-solutions-amphibian-monitoring-adapting-autonomous
We are working on adapting BirdNET to detect Patagonian anuran species from passive acoustic monitoring recordings. As you can imagine, we have run into several practical dilemmas when defining labeling criteria—challenges that likely also arise in other projects involving birds, bats, or other taxa.
Here are some of the questions we are grappling with:
- Label duration: Is it better to create short, simple labels (which may increase false positives) or longer, more precise ones (which could increase false negatives)?
- Quality categories: Should we classify labels into multiple categories based on signal-to-noise ratio, or are 2–3 categories sufficient (e.g., good, fair, poor)?
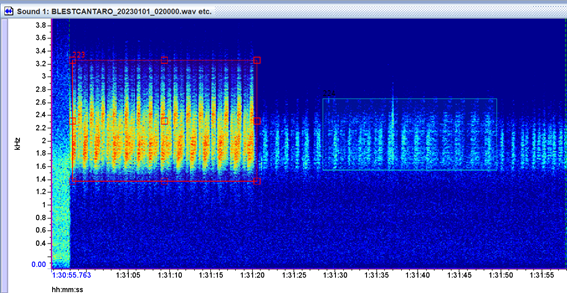
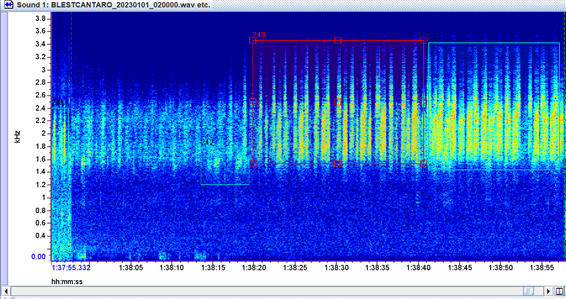
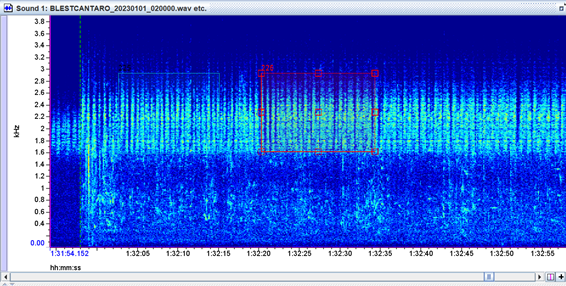
- Choruses and overlapping signals: When a chorus of many individuals of the same species dominates the recording, how should we decide whether the label is “high quality” (due to volume and clarity) or “fair” (because of the difficulty in separating individual calls)?
We’d like to open this discussion so that everyone can share experiences, examples, and decision-making criteria. We believe such an exchange could help bring different projects closer together and, ultimately, support the development of common labeling protocols that make dataset reuse easier.
Has anyone else faced these kinds of decisions in their projects?
How have you balanced accuracy, consistency, and the volume of labeled data?
Hola a todos.
👉En el marco del proyecto …
https://wildlabs.net/discussion/wildlabs-awards-2025-open-source-solutions-amphibian-monitoring-adapting-autonomous
estamos trabajando en la adaptación de BirdNET para detectar especies de anuros patagónicos a partir de grabaciones de monitoreo acústico pasivo. Como imaginarán, nos hemos encontrado con varios dilemas prácticos a la hora de definir los criterios de etiquetado, que seguramente también aparecen en otros proyectos, ya sea con aves, murciélagos u otros taxones.
Algunos ejemplos de las preguntas que nos surgen:
- Duración de las etiquetas: ¿es mejor generar etiquetas cortas y simples (que probablemente aumenten los falsos positivos), o etiquetas más largas y precisas (que podrían aumentar los falsos negativos)?
- Categorías de calidad: ¿conviene clasificar las etiquetas en muchas categorías según la relación señal-ruido, o basta con 2–3 (ej. buena, regular, mala)?
- Coros y señales múltiples: en casos en los que hay un coro de muchos individuos de la misma especie en primer plano, ¿cómo decidir si la etiqueta corresponde a "alta calidad" (por volumen y claridad) o a "regular" (por la dificultad de separar cantos individuales)?
Nuestra idea es abrir la discusión aquí para que cada persona comparta su experiencia, ejemplos concretos y criterios de decisión. Creemos que este intercambio puede ayudar a acercar posiciones entre distintos proyectos y, eventualmente, a pensar en protocolos comunes de etiquetado que faciliten la reutilización de datasets.
¿Alguien más ha enfrentado estas decisiones en sus proyectos?
¿Cómo resolvieron el balance entre precisión, consistencia y volumen de datos etiquetados?
@boninom @VMRocchi @javierareta @mdenham @marianbasti @cpozzi @Anabellacarp
3 September 2025 9:03pm
Excelente inciativa Enrique! como estamos viendo los criterios de etiquetado son un aspecto crucial para un buen desempeño de los algoritmos de identificación automática. Espero que esta discusion sea activa y tengamos muchas interacciones!
Marcelo Bonino
National Scientific and Technical Research Council of Argentina (CONICET)