
Talia Speaker
Effective wildlife management depends upon good population data. Over the past two decades, camera traps have revolutionized field-data collection, but efficient processing of the collected data remains a challenge. Although many attempts have been made to automate image processing using machine learning, most did not achieve high enough accuracy rates to be useful in practice until recently. One of the first major successes on this front appeared in April of 2017 when a team of researchers at the University of Wyoming used deep convolutional neural network models to successfully identify 48 East African wildlife species with a 92% accuracy rate. Over the following months, I applied their models to a novel data set from a neighboring Tanzanian national park.
Background
During my years as an undergrad, I spent countless hours sorting through camera trap images. I was astounded by the inefficiency of manual processing programs, but my higher-ups rarely seemed to share my motivation to improve the system. When I asked a supervisor about exploring better options once, he shrugged and said, “Someday I’m sure robots will do it for us, but good thing we have interns like you for now!” That day I swore to myself I wouldn’t classify another camera trap image until I had found a better system.
Not long after, I returned from a semester abroad in Tanzania with a USB drive containing more than 111,000 unclassified camera trap images. As I still hadn't found a better system, I decided to try to make one myself. I got the blessing of my advisor Dr. Christian Kiffner with the School for Field Studies to use the data, secured a grant from my school (Scripps College), and got to work turning this project into my senior thesis. Why my funders (or I, for that matter) thought a third-year organismal biology major with no background in computer science could take on such a project still boggles me, but I am certainly grateful that they supported this moment of eager over-confidence.

A sample camera trap image from the Lake Manyara Park dataset, collected by professors at SFS Tanzania.
Just as I was recognizing the scope of my proposed project and how very little I knew, I found a recently-published paper by Mohammad (Arash) Norouzzadeh and his team at the University of Wyoming's Evolving AI Lab. They had done everything I had dreamed of doing and more – and they had even used the same species! Their deep neural network models were the ones achieving a 92% hit rate and they had been trained on the Snapshot Serengeti images, which made up the largest validated camera trap data set in the world. I emailed the lab and asked to use their trained models, proposing a validation study. They said yes with one caveat – I had to learn how to use them myself. How hard could that be?
The System
I spent the first part of the summer of 2017 building a hardware system that would support running the pre-trained neural network models. After identifying what I needed by falling (very) short with three existing systems – my MacBook Air, a friend’s dual-GPU Windows system, and an old Linux desktop – I turned to Kevin Bell, a computer whizz, friend, and research fellow at nearby UC Santa Cruz. He happened to have a stockpile of hardware hanging around “just in case,” from which he generously loaned me a few key elements for the project. The final system included a 3 TB hard drive, an NVIDIA Geforce GTX 650 GPU, and an Intel Core i7 processor operating on 64-bit Ubuntu 16.04 LTS. It wasn’t exactly beautiful, but it did the job.

My DIY computer system
This original version of the code from Arash and his team was based on a framework in Torch, a scientific computing framework for LuaJIT, so I got Torch and other software required for it to function properly installed on the new system. Finding the correct drivers and correct versions of everything for mutual compatibility was definitely a non-trivial effort for a novice like myself. The term "fatal error" made more than one appearance, much to my chagrin, before I had the system ready to run.
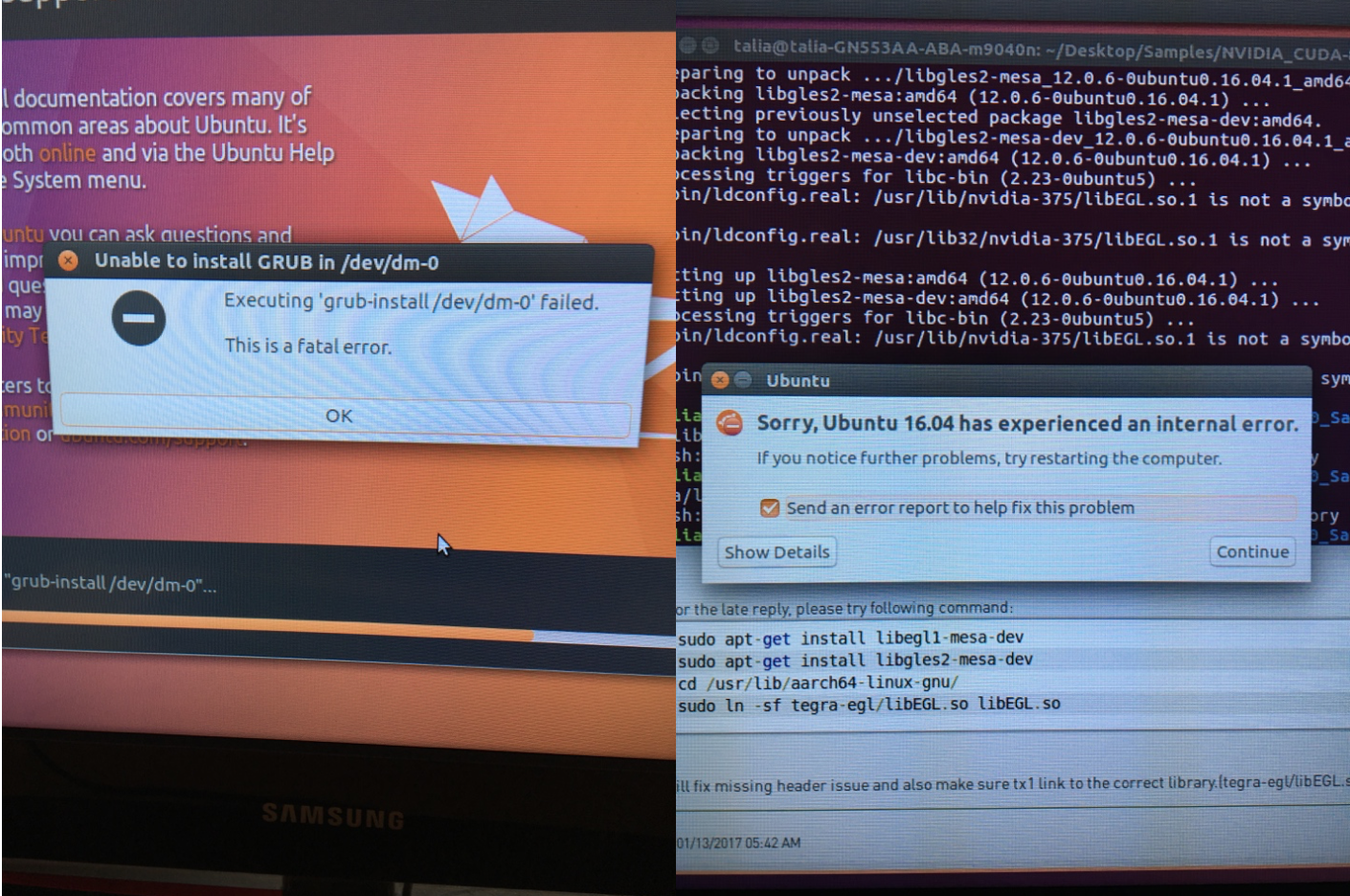
Running the Models
The repository from Arash and his team consisted of modifications of standard Lua files for operating in Torch, as well as two pre-trained models: one to classify “animal” images from “empty” ones (i.e. false triggers), and another to separate them by species.
The code from Arash was comprehensive, building the models from training images. I only needed to apply the models to classify my images, so some rewriting was needed. Unfortunately, the documentation for the Lua language is much less robust than more widely-used languages like Python, so identifying the necessary alterations was a challenge. With the help of a computer science major from neighboring Harvey Mudd College, I transferred the project from Torch to PyTorch to simplify the process. In Python, finding the right commands was often as simple as a quick Google search.
When at last we got the models loaded, the images pre-processed correctly, and the predictions loading, I could hardly breathe in anticipation as we awaited the results. Because of some differences in camera models and positioning, habitat, weather, etc. between my data set and that of Snapshot Serengeti, I wasn’t sure how accurate the models would be on these new images without additional training. However, with Lake Manyara National Park only about 170km from Serengeti NP, I hoped for a decent success rate - all of these differences were minor, and all but one species overlapped between the datasets.
Results
When at last the results came in, we found something strange. The “animal” vs “empty” model seemed to work beautifully (96% accuracy on a mini sample of 50 images), but the species ID model had identified every single “animal” image as a kori bustard. Kori bustards, the world's heaviest flying birds, just happened to be the ONLY species in the Serengeti dataset that did not occur in the Lake Manyara images. The irony was painful.

Male kori bustard, Maasai Mara National Reserve, Kenya (© Christina Krutz/Masterfile)
After a long and ultimately unfruitful process of trouble-shooting between my programmer friend, Arash, and myself, I was out of time and had to take my thesis in a different direction. However, while I finished that up and graduated, Arash and his team developed new and improved versions of their models, now in Tensorflow (along with this paper). I sent over a sample set of Lake Manyara images to try on these models, and the results came back without a hitch. The predictions were just under 70% accurate, but it was only a handful of images, and hey, at least they weren't kori bustards.
Take-Aways
While the tech industry is gaining increasing capacity to revolutionize wildlife monitoring, these advancements, as WILDLABS members know all too well, are only useful to the extent that they are made accessible to users in the field. Granted, I was far less prepared than most would be taking on a validation study of this kind, and Arash's team had not yet attempted to make their program user-friendly, but I dove headlong into that space between innovation and application nonetheless, and I struggled to bridge the gap. None of my PhD-holding, wildlife-expert advisors had any idea how to help me once I got into the realm of coding, and none of the computer science professors I reached out to were interested enough in conservation to dedicate time to the effort. That is where WILDLABS could have come in, had I known it existed a year ago. Throughout this process, I wished more than anything for a community like ours, which is why I am thrilled to be helping others take advantage of it now as the WILDLABS Intern.
Shortly after I got news of the updated code, I left home in California to start my position here based at WWF in Washington, DC. As my clunky DIY computer system didn’t make the luggage cut for my cross-country flight, I have yet to try running the whole Lake Manyara dataset through the updated models. However, Arash and others, including Michael Tabak, are also currently working on a new paper (which Ollie Wearn shared with the Camera Traps group in this thread a while back) that includes an R package to do automated species ID on camera trap images. Maybe by the time I’m reunited with my system, processing these images will be as easy as a few commands in R!
While I was only partially successful in processing the Lake Manyara data set in this first attempt, the project introduced me to the world of AI as a key player in the future of conservation tech, and ultimately led me to WILDLABS. It was also a lesson in the process of innovation - turning my frustration with an outdated system into an opportunity to develop an alternative taught me more than I could have ever learned in a classroom. There was no way I was going to achieve any useful level automated species recognition starting from scratch on my own that year, but in my eagerness to attempt it I discovered partners, the power of networking, and eventually a community already dedicated to ensuring the progress of this revolutionary technology on the brink of widespread accessibility.
About the Author
Talia Speaker recently graduated from Scripps College with a degree in Organismal Biology. She joined WILDLABS as a member in January of 2018 and as our intern in July. Most of her work experience thus far has been wildlife-based field research, studying large mammal ecology, HWC, and community-based conservation in Tanzania, and puma behavior at home in Santa Cruz, CA. While her interest in conservation tech had been growing for years through her work with camera trapping and radio telemetry, this species recognition project opened her eyes to the exciting potential for AI in conservation and solidified her intent to pursue a career in this field.
Add the first post in this thread.